Published in the Data Mining and Knowledge Discovery journal.
Code can be found at this repository.
Plain-language summary can be found in this post.
See also the page on training-free cloud removal for EO data, which uses and extends VPint to remove clouds from satellite images.
Abstract
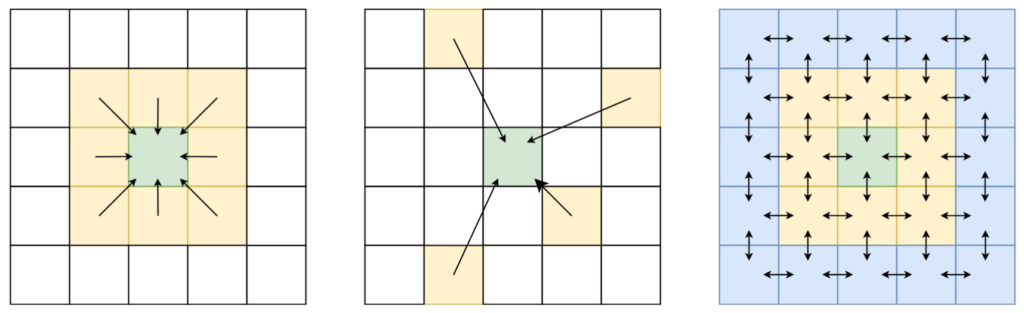
Given the common problem of missing data in real-world applications from various fields, such as remote sensing, ecology and meteorology, the interpolation of missing spatial and spatio-temporal data can be of tremendous value. Existing methods for spatial interpolation, most notably Gaussian processes and spatial autoregressive models, tend to suffer from (a) a trade-off between modelling local or global spatial interaction, (b) the assumption there is only one possible path between two points, and (c) the assumption of homogeneity of intermediate locations between points. Addressing these issues, we propose a value propagation-based spatial interpolation method called VPint, inspired by Markov reward processes (MRPs), and introduce two variants thereof: (i) a static discount (SD-MRP) and (ii) a data-driven weight prediction (WP-MRP) variant. Both these interpolation variants operate locally, while implicitly accounting for global spatial relationships in the entire system through recursion. We evaluated our proposed methods by comparing the mean absolute error, root mean squared error, peak signal-to-noise ratio and structural similarity of interpolated grid cells to those of 8 common baselines. Our analysis involved detailed experiments on a synthetic and two real-world datasets, as well as experiments on convergence and scalability. Empirical results demonstrate the competitive advantage of VPint on randomly missing data, where it performed better than baselines in terms of mean absolute error and structural similarity, as well as spatially clustered missing data, where it performed best on 2 out of 3 datasets.
Updates since publication
- Numerical stability: At the time of publication, VPint worked well on most data, but had occasional, rather extreme outliers with terrible performance. Although the method still had plenty of advantages, I am happy to say that this issue was addressed while working on the cloud removal project. The issue appears to have been caused by unreasonable weights being predicted due to numerical stability issues with near-zero feature values and their ratios. This caused values to occasionally increase at an unreasonable rate, which the system-oriented approach inadvertently amplified. Although a weight regularisation type approach was considered, we found that simply clipping values to a reasonable maximal value was sufficient to stop the issues we encountered; the newest version of the code already incorporates this option. The clip value does not need to be set too aggressively, as the main point is to prevent extreme values from being propagated, not to protect individual cell values.