

Please see also the project page for this paper.
Why cloud cover matters so much for EO data
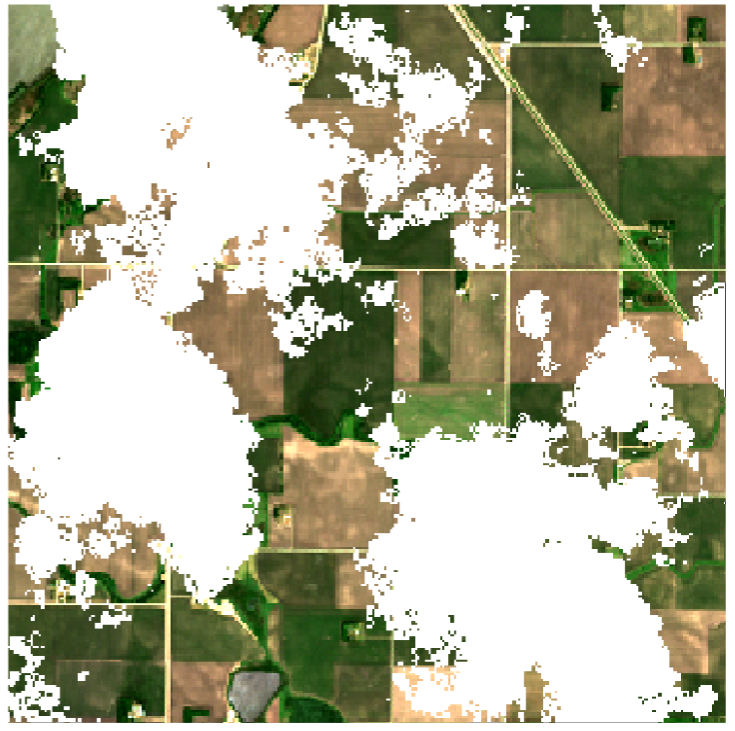
Most of the Earth observation (EO) satellites currently in orbit are a little bit like fancy cameras: they measure a light spectrum. Unlike a regular camera, which just measures light intensity at the visible wavelengths humans can see (red, green and blue), the spectrometers (fancy cameras) on satellites measure light intensity at many different wavelengths, including ultraviolet and infrared. However, for most sensors, the light the satellite is trying to measure cannot pass through clouds, the same way you and I cannot see what is going on in the sky behind the clouds when we look up on a cloudy day. The clouds are basically photobombing our satellite imagery, which is not what we spent all that taxpayer money on! We want to know what is going on underneath the clouds!
So when there are clouds in the sky, we can’t look through them, and that’s bad. Still, is it really that big a deal? Surely there are enough clear days to take a picture instead? Well, not really. First of all, at any given time, between 55% and 72% of the Earth is covered by clouds on average. You have to get quite lucky so that your one picture every 5 days (in the case of the popular Sentinel-2 satellite) exactly hits a gap in the cloud cover that covers the full spatial extent of your image. However, even this figure understates how big a problem cloud cover can be.
Clouds are not evenly spread over the Earth and its seasons. Countries near the equator are cloudy year-round, while countries further removed from the equator experience seasons. There, most of the cloud-free images we can capture are concentrated in the sunny summer, while in winter, it can be hard to get any feasible measurement at all for months on end.
For these reasons, we need methods capable of removing clouds from our satellite imagery, returning a full image with estimated values for the cloudy pixels.
VPint2 for cloud removal
We realised that our spatial interpolation method, VPint (see also its project page and plain-language explanation; in the following I will assume a knowledge of the original method), could be very well suited to this problem, offering substantial advantages over existing methods. However, this required us to add substantial extensions to the algorithm, prompting a name change to “VPint2”.
From predicted weights to exact reference weights
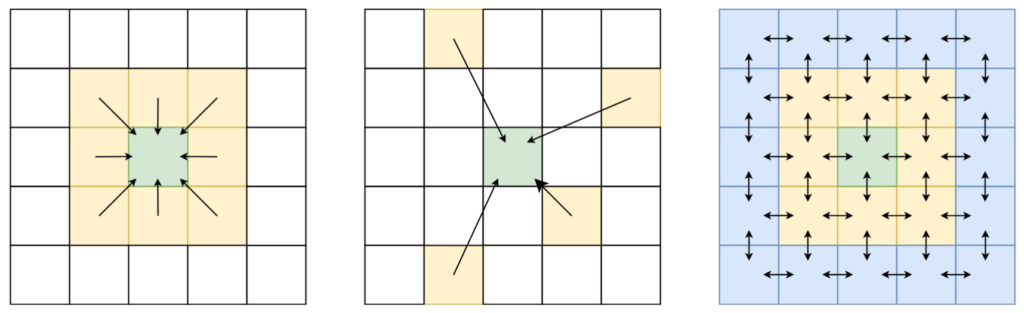
As you may recall, in WP-MRP, we predicted neighbour-specific weights based on some spatial features, to enable our spatial interpolation method to account for certain trends in the spatial structure. In EO settings, we can take this philosophy one step further: we don’t just need to model trends, we need to reconstruct an image with exact, sharp borders between objects.
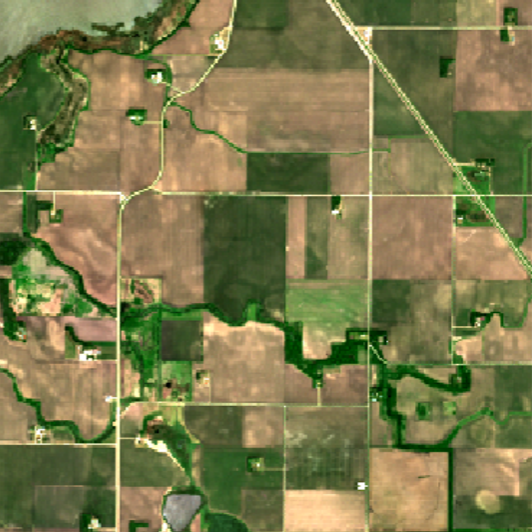
Thankfully, EO satellites keep taking pictures of the same area over and over again. While the situation on the ground may change over time (for example, trees turn from green, to golden brown, to completely without leaves), the spatial structure, and the “objects” it describes, remains relatively stable (a forest doesn’t disappear just because the state of the trees changes).
This is a property we can exploit to apply VPint2 to image reconstruction tasks instead of the general spatial interpolation tasks of the original VPint: we have the ultimate, extremely correlated weight features, available for direct computation in previous measurements! We simply compute the weights between all neighbours in a cloud-free reference image, and use those as the weights to perform VPint interpolation. This approach proved to be highly effective! However, there were still a few stability issues to iron out.
Improving stability and performance
There were two main issues that kept bugging us while working on this project.
First, we found that sometimes, strange colours from one object could “bleed” into another object. Although we assume that the spatial structure remains mostly stable over time, sometimes different objects can evolve differently over time. For example, imagine there were two objects in a summer reference image: a green forest, and a black asphalt road next to it. Next, in our cloudy autumn image, the forest turned golden brown, but the road remained black. The spatial structure remained mostly intact, because neighbours within objects were still very similar to one another, but at the borders, the spatial structure had changed: the relationship between objects had changed.
For this reason, we added a functionality we named identity priority. Basically, if we can choose between using information from the same object, or from a different object, we put a lot more faith into the information from pixels in the same object. We found that, in most cases, enabling this feature improved reconstruction performance — even in images where we couldn’t even see any visually apparent artefacts!
Second, sometimes the reconstruction would, for lack of a better word… go completely insane. Seriously, we would just get reconstructions with values in the order of magnitude 10^250. In the end, we figured out what had happened. Satellite data is flawed. Sometimes, there’s a pixel value that’s not quite right, either way too low, or way too high. To compute weights in the reference image, we divide one pixel value by another. If one of these values gets close to 0, we end up with some rather extreme multipliers, either very close to 0, or very large (depending on the direction). So, how did we solve this?
One step to reducing the impact of this issue is to simply constrain values not to exceed some maximal value, following similar preprocessing techniques to those used by other cloud removal methods. However, we also wanted a more elegant solution, so that a hard threshold is only used as a last resort. In the end, we created a feature we dubbed elastic band resistance.
Hopefully, the elastic band analogy makes the concepts easy to understand. Imagine the values of a pixel as the movement of an elastic band. Up to a certain point, you can move the band as far as you want. However, at some point, you hit the full length of the elastic band. If you want to move it further away, you can do so, but you will need to stretch the band to do it. At first, this is quite easy, but the further away you try to move, the more resistance the band will give to your push, and the more effort you will need for a relatively small movement.
This concept is what we applied to our method. Up to a certain threshold, pixel values could increase freely. After this threshold, any further increase in value is penalised based on how much the threshold is already exceeded, with larger excesses resulting in more resistance and smaller additional increases. We found this feature, combined with the “last resort” of clipped values, to effectively address the issues caused by faulty pixels and extreme weights.
Finally, in addition to identity priority and elastic band resistance, we greatly improved how fast VPint2 could perform cloud removal by adding parallel computing. Those who are curious about this aspect may be interested in the Bachelor thesis by my former student Dean, who worked on this topic.
Conclusion
In my experience, VPint2 is the easiest possible cloud removal method to use, short of just mosaicking past cloud-free pixel values (which, in terms of numerical performance, would be a very large sacrifice). I would encourage anyone who works with cloudy ground-level data to give it a try. After publication, I wrote a previous blog post as a quick tutorial for how to use the algorithm for your data. If you run into any issues despite these instructions, please feel free to get in touch, so that I can add or update material for further ease of use!
We are also currently looking into creating a cloudy time-series version of the method, removing the reliance on a single, fully cloud-free reference image. I’d also be interested in exploring avenues for getting the algorithm added to ESA’s SNAP tool, or data access point like Google Earth Engine or SentinelHub.